Yapay Zeka çılgınlığının trend olduğu bu günlerde, nerdeyse her fenomenin bir bilgi seli yağmuruna bizleri maruz bıraktığı ChatGPT hakkında bilgi vermek bizimde buyun borcumuz oldu. Tabii fırsat kalırsa!
Gerçekten de muazzam bir hızda ilerleyen bu fırtına gelecek açısından bir çok değişim ve devrimin habercisi olma niteliğinde. İşin manüplatif ve magazinsel tarafını bir kenara atarak, gerçekten de kamera arkasında nelerin döndüğünü anlamanın zamanı geldi. Bu yazı, bu modanın öncüsü olan ChatGPT’nin tarihsel evrimini ve mimarisini açıklamak ve de anlamak için hazırlanmıştır. Şimdiden iyi seyirler…J
Şimdi size bir görev, ChatGPT kelimesini ortadan ikiden ayırın. Soldaki kısım herkesin bildiği Chat kelimesinin anlamı malumunuz. Bizim için önemli olanı GPT kısmı. Önce bu kısaltmanın İngilizce açılımını yazalım. Generative Pre-trained Transformer yani Türkçe meali: Üretken Ön İşlemeli Dönüştürücü. Şimdi bu ifadenin temel lokomotifi olan Transformer (Dönüştürücü) kavramını anlamaya çalışacağız. Bunun için şu an ChatGPT uygulamasının kullandığı modellerin (GPT 3.5 ve GPT4) atalarını tanımlayıp sürecin evrimini irdeleyelim.
Bilindiği gibi ChatGPT, OpenAI tarafından geliştirilen bir dil modelidir. Kuruluş amacından farklı mecralara savrularak zenginliği ve şöhreti seçen OpenAI ekibi 2018 yılında yapay zeka aleminin ilk Lucy’si (ilk insan) olan GPT modelini ürettiğini lanse etti. Bunu yaklaşık bir yıl sonra GPT2 ve 2020 yılında ise GPT3 modeli izledi. Buraya kadar süreç daha çok bilişim dünyasında ve akademide farkındalık yaratarak ilerledi. En azından ülkemizde diyelim!
Dananın kuyruğunun koptuğu tarih Kasım 2022 oldu. GPT 3.5 olarak lanse edilen ChatGPT uygulaması herkesin kullanımına açılarak adeta tüm dünya da şok etkisi yarattı. Daha önce filmlerde gördüğümüz ürkütücü senaryolar artık beyaz perdeden bilgisayarımıza iliştirildi. Bu şok OpenAI ekibine az gelmiş olacak ki müthiş bir pazarlama stratejisi örneği olacak şekilde GPT 3.5 dil modelinin neredeyse 100 katı kadar parametreyle eğitilmiş GPT4 modeli uygulamaya sokuldu. Son bir fark ise bu modelin kullanımı 20 $ gibi Batılılar için çerez, bizim için bir günlük yevmiyemizden fazla olan bir ücrete tabii olmasıydı. Ardından bu model üzerine kurulu birçok uygulama ve arayüz tasarımları piyasaya sürüldü. Halen de gün geçmiyor ki yeni tasarımlarla karşı karşıya kalmayalım.
Neyse biz konumuza geri dönelim. Nedir bu Transformerler ve bizden ne istemektedir?
Doğal Dil İşleme (NLP), metin sınıflandırma, dil modelleme, makine çevirisi gibi görevlerin çoğu, dizi modelleme (sequence modeling ) görevlerinden oluşur. Geleneksel makine öğrenimi modelleri ve sinir ağları, kelime merkezli işlem yaptığı için metinde bulunan sıralı bilgileri yakalayamaz. Bu nedenle, araştırmacılar tekrarlayan sinir ağlarını (RNN ve LSTM) geliştirdi. Bu mimariler metinde bulunan sıralı bilgileri modeller. Bununla birlikte, bu yapıların da sorunları bulunmaktaydı. Önemli bir sorun, RNN’lerin paralelleştirilememeleridir, çünkü her seferinde bir girdi almaktadırlar. 2018’de Google OPEN AI ekibi tarafından yayınlanan “Attention is All You Need” makalesi yeni bir devrimin işaret fişeği olan Dönüştürücüler (Transformers) modelini tanıtarak NLP’de çığır açtı.
Transformatörler, her katmanında birden fazla dikkat ögesi içeren ve çoklu katmanlardan oluşan yapılardır. NLP’de Transformatörler, uzun menzilli bağımlılıkları kolaylıkla ele alabilmelerinin yanında diziden diziye görevleri çözmeyi amaçlayan bir mimariye de sahiptir. Transformatörün arkasındaki fikir, giriş ve çıkış arasındaki bağımlılıkları dikkatle (attention) ve yineleme (recurrence ) ile tamamen ele almaktır. Transformatör tabanlı modelleri kullanmanın birçok avantajı vardır, ancak en önemlileri şu şekilde sıralanabilir. İlk fayda, bu modeller, bir giriş dizisini belirteç (token) olarak işlemezler, bunun yerine tüm diziyi tek seferde girdi olarak alırlar. Geleneksel sıralı veya tekrarlayan modellerin aksine, dikkat mimarisi tüm girdi dizisini bir kerede işler. Bu, RNN tabanlı modellere göre büyük bir gelişmedir. Başka bir fayda ise; bu modelleri önceden eğitmek için etiketlenmiş verilere ihtiyaç bulunmamasıdır. Bu, transformatör tabanlı bir modeli eğitmek için çok büyük miktarda etiketlenmemiş metin verisi sağlanması gerektiği anlamına gelir. Bu eğitimli modeller, metin sınıflandırması, adlandırılmış varlık tanıma, metin oluşturma gibi NLP görevleri için kullanılır. BERT ve GPT-3 en popüler transformatör tabanlı modellerdir. Bidirectional Encoder Representations for Transformers (Transformatörlerden Çift Yönlü Kodlayıcı Temsilleri) ifadesinin kısaltması olan BERT; çift yönlü, hem sol hem de sağ bağlamda ortak koşullandırma yoluyla etiketlenmemiş metinden derin çift yönlü temsilleri önceden eğitmek için tasarlanmıştır.
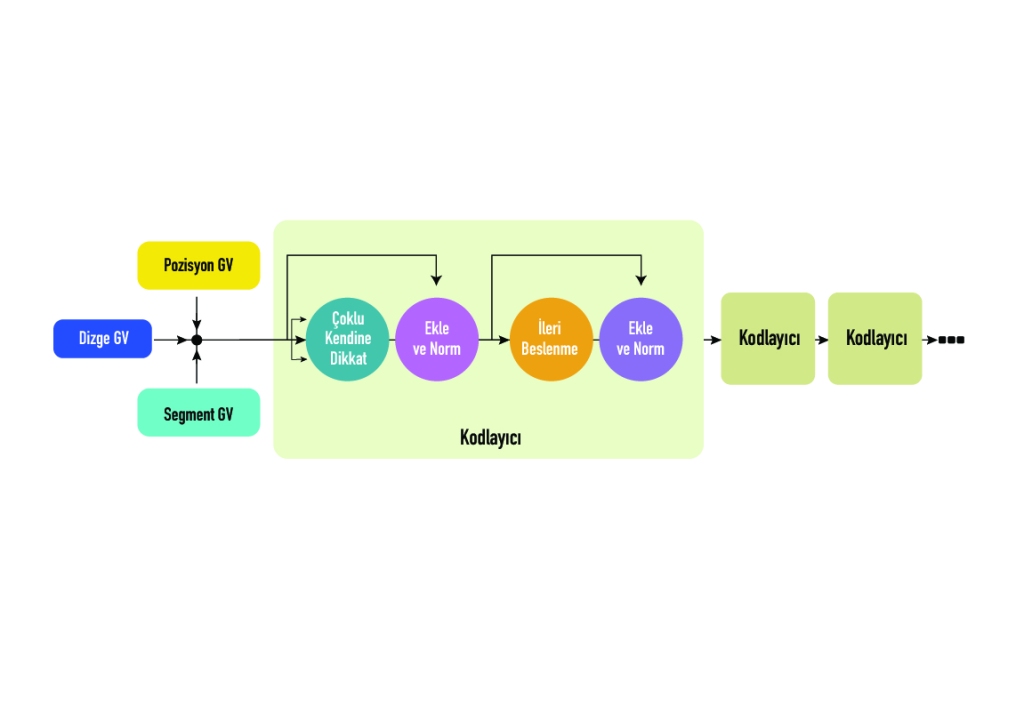
Şekilde görüldüğü gibi, Transformatör’in ilk katmanı, girdi olarak dizge (token), pozisyon (positional) ve segment gömme (embedding) vektörlerinin bir kombinasyonundan. Bunlardan ilki; girdi cümlesinin sayısal temsilini, ikincisi dizgelerin cümlede bulunduğu konumu ve sonuncusu ise dizgenin hangi cümlede olduğunu belirtir. İlk süreç bu üç vektörün toplanarak kodlayıcılara gönderilmesiyle başlar. Böyle kapsamlı bir gömme şeması, model için birçok yararlı bilgi içerir. Böylece, modelin mimarisinde büyük bir değişiklik yapılmadan eğitmek kolaylaşır. Her Transformer bütünleşik bir ikili yapılı olan Otokodlayıcılardan (Encoder- Decoder) oluşur. Bunlar denetimsiz bir şekilde eğitilen, verinin kodlanmış gösterimini öğrenip daha sonra bu kodlanmış gösterimden girdi verisini mümkün olan en yakın şekilde üreten yapay sinir ağlarıdır. Encoder ve Decoder blokları aslında birbirinin üzerine yığılmış birden çok özdeş kodlayıcı ve kod çözücüdür. Hem kodlayıcı yığını hem de kod çözücü yığını aynı sayıda birime sahiptir. Her bir kodlayıcı (Encoder) bloğunda bir tane Çoklu Dikkat Ağı (Multi-Head Attention) ardından da İleri Beslemeli (Feed Forward) Sinir Ağı katmanı bulunur. Kod çözücüde (Decoder) ise buna ek olarak ekstra bir Maskelenmiş Çoklu Dikkat Yapısı (Masked Multi-Head Attention) bulunur. Çoklu dikkat yapısı, modelin farklı konumlardaki farklı temsili alt uzaylarından gelen bilgileri ortaklaştırarak ağa katılımını sağlar. Bu katmanlar “Ekleme&Normalize” (Add & Norm) ile gösterilen kutularla birbirine bağlanırlar. “Add” kısmı artık (Residual) bir bağlantı olduğunu gösterir ve bu da gradyanın yok olmasını engeller. Norm kısmı ise katmanın normalizasyonunu belirtir. Bu aşamada Dikkat (Attention) yapısının önemi üzerine durmakta fayda olacaktır.
Dikkat Yapısı Nedir?
Dikkat, bir sorguyu (Query), bir dizi anahtar-değer (KeysValues) çiftini ve çıktının tümünü belirli ağırlıklar doğrultusunda vektörel bir sonuca dönüştürme işlemi olarak tanımlanabilir. Dikkat ağırlıkları (Attention weights), mevcut dizge için bir sonraki temsili üretirken diğer tüm dizgelerin ne kadar “önemli” olduğunu belirleyen bir yönelim olarak görülebilir. Tahmin edilecek ve bağlam hakkında fikir veren kelimelere sorgu (Q), önceki tahminler için kullanılan şu anki kelime ile ilgili bilgi taşıyan etiketler anahtar (K) ve kelimelerin içeriklerini temsil eden yapılar ise değer (V) olarak adlandırılır. Dikkat fonksiyonunu bir matris halinde paketlenmiş bir dizi sorgu üzerinde aynı anda hesaplanır ve eş zamanlı olarak anahtar ve değer yapılarıyla bütünleştirilir. Sonuç matrisi şu şekilde hesaplanır;
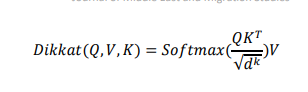
İç çarpımda ölçeklendirme yapmak için notasyonda 1/d düzeltmesi kullanılır. ; d anahtar vektörünün boyutunu ifade eder. Öz dikkat yapısı her boyut için ayrı hesaplamalar yapar. Bununla birlikte, Çoklu Dikkat yapısı kullanılarak, modelin farklı konumlardaki farklı temsil alt uzaylarından gelen bilgiler iç çarpım (dot product) aracılığıyla final değeri oluşturulur. Tek bir dikkat başlığı ile ortalama alma bunu verimli bir şekilde sağlayamaz. Böylece modelin farklı pozisyonlara odaklanma yeteneği genişler.
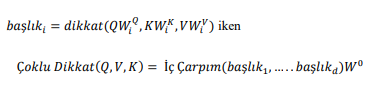
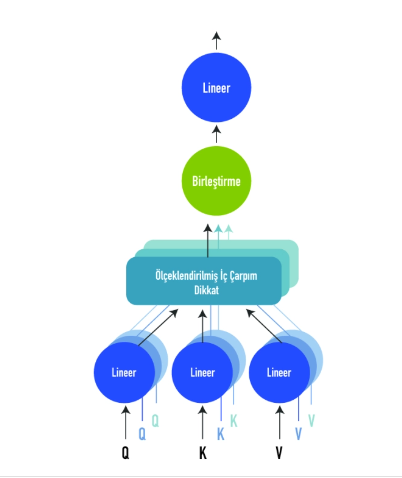
Şekil 2. Çoklu Dikkat Yapısı
Bu arada, Pre-trained kelimesinin açıklamasını da bonus olarak açıklayalım.
Modern NLP sistemlerinin önemli bir bileşeni olarak önceden eğitilmiş (pre-trained ) kelime gömme tekniği, sıfırdan öğrenilen yerleştirmelere göre önemli iyileştirmeler sunar. Cümle gömmeleri veya paragraf gömmeleri gibi sözcük gömmelerinin genelleştirilmesi de alt modellerde özellik olarak kullanılır. Transfer öğrenimi, büyük bir veri kümesi üzerinde eğitilmiş bir derin öğrenme modelinin başka bir veri kümesinde benzer görevleri gerçekleştirmek için kullanıldığı bir tekniktir. Böyle bir derin öğrenme modeline önceden eğitilmiş bir model denir. Son zamanlarda, büyük miktarda etiketlenmemiş veri içeren büyük bir ağ üzerinde dil modellerini önceden eğitme ve alt görevlerinde (downstream) ince ayar(fine-tuning) yapma yöntemi, birçok doğal dil anlama görevinde bir atılım yaptı . Bir metin dizisi durumunda, bir RNN veya LSTM, girdi olarak her seferinde bir dizge (token) alır. Böyle bir modeli büyük bir veri kümesi üzerinde eğitmek çok zaman gerektirir. Bu nedenle, NLP’de transfer öğrenmeye duyulan ihtiyaç tüm zamanların en yüksek seviyesindedir ve genel eğilim bu yöne doğru hızlı bir akış gösteriyor.
Bu yazıda sizlere GPT modellerinin teorik alt yapısını açıklamaya çalıştık. Yoğun matematik ve derin öğrenme alt yapısının olduğu alanı bir kerte de anlamak çok zor. Bunun farkındayız. Ancak dikkatini bu konuya celp eden genç araştırmacılara ısınma turu mahiyetinde bu hap bilgileri sunmak bizim için elzem bir görevdi.
Sağlıcakla kalın.
Önemli not: Bu yazıda ki tek bir kelime bile ChatGPT’ye yazdırılmamış olup bizatihi yazar tarafından hakaret olarak kabul edilmektedir.:)